

یک فایل robots.txt حاوی دستورالعملهایی برای رباتها است که به آنها میگوید به کدام صفحات وب میتوانند دسترسی داشته باشند و به کدام صفحات نباید بروند. فایلهای robots.txt برای خزندههای وب موتورهای جستجو مانند Google مرتبط هستند.
فایل robots.txt مجموعه ای از دستورالعمل ها برای ربات ها است. این فایل در میان فایلهای منبع اکثر وب سایتها قرار دارد. فایلهای robots.txt بیشتر برای مدیریت فعالیتهای رباتهای خوب مانند خزندههای وب در نظر گرفته شدهاند، زیرا رباتهای بد اصلاً دستورالعملها را دنبال نمیکنند.
یک فایل Robots.txt را مانند یک علامت “بخشنامه” در نظر بگیرید که روی دیوار یک باشگاه ورزشی یا یک مرکز اجتماعی نصب شده است: این بخشنامه به خودی خود قدرت اجرای قوانین ذکر شده را ندارد، اما مشتریان “خوب” قوانین را رعایت خواهند کرد، در حالی که مشتریان “بد” آنها را زیر پا میگذارند و ممنوعیتی برای خود قائل نیستند.
- فایل robots.txt چیست؟
- فایل robots.txt چگونه کار میکند؟
- چه پروتکل هایی در فایل robots.txt استفاده میشود؟
- آشنایی با دستورات فایل Robots.txt و معانیشان
- پروتکل سایت مپ چیست؟ چرا در robots.txt گنجانده شده است؟
- چگونه یک فایل robots.txt ایجاد کنیم؟
- چگونه فایل robots.txt را آپلود کنیم؟
- چگونه فایل robots.txt را به گوگل ارسال کنیم؟
- robots.txt چگونه با مدیریت ربات ارتباط دارد؟
- تاثیر فایل Robots.txt
فایل robots.txt چیست؟
ربات یک برنامه کامپیوتری خودکار است که با وب سایت ها و برنامه های کاربردی تعامل دارد. برخی رباتها خوب و برخی دیگر رباتهای بد هستند. یک نوع ربات خوب، ربات خزنده وب نامیده میشود. این رباتها صفحات وب را «خزش» میکنند و محتوای آن را فهرستبندی میکنند تا در نتایج موتورهای جستجو نمایش داده شوند.
فایل robots.txt به مدیریت فعالیتهای این خزندههای وب کمک میکند تا بر سرور وب میزبان وبسایت، یا فهرستبندی صفحاتی که برای نمایش عمومی نیستند، هزینه بار اضافه نکنند.
فایل robots.txt چگونه کار میکند؟
robots.txt فقط یک فایل متنی بدون کد نشانه گذاری HTML است . این فایل مانند هر فایل دیگری در وب سایت بر روی وب سرور قرار میگیرد. در واقع، فایل robots.txt برای هر وبسایت معینی را معمولاً میتوان با تایپ URL کامل برای صفحه اصلی و سپس افزودن /robots.txt، مانند https://www.cloudflare.com/robots.txt مشاهده کرد. این فایل به جای دیگری در سایت لینک داده نشده است، بنابراین کاربران به احتمال زیاد آن را نخواهند دید، اما اکثر رباتهای خزنده وب ابتدا قبل از خزیدن سایت، این فایل را جستجو میکنند.
فایل robots.txt دستورالعمل هایی را برای ربات ها مشخص میکند. یا میگوید کدام دستورالعمل ها را اجرا نکند. یک ربات خوب، مانند یک خزنده وب یا یک ربات فید خبری، سعی میکند قبل از مشاهده هر صفحه دیگری در یک دامنه، ابتدا از فایل robots.txt بازدید کند و دستورالعمل های آن را دنبال کند. ربات بد یا فایل robots.txt را نادیده میگیرد یا آن را بررسی میکند تا صفحات وب ممنوعه را پیدا کند.
یک ربات خزنده وب از خاصترین مجموعه دستورالعمل ها در فایل robots.txt پیروی میکند. اگر دستورات متناقضی در فایل وجود داشته باشد، ربات از دستور granular بالاتر پیروی میکند.
نکته مهمی که باید به آن توجه داشت این است که همه زیر دامنه ها به فایل robots.txt خود نیاز دارند. به عنوان مثال، دامنه www.cloudflare.com فایل مخصوص به خود را دارد، همه زیر دامنه های Cloudflare (blog.cloudflare.com، community.cloudflare.com و غیره) نیز به فایل خود نیاز دارند.
چه پروتکل هایی در فایل robots.txt استفاده میشود؟
در مبحث شبکه، پروتکل قالبی برای ارائه دستورالعملها یا دستورات است. فایلهای Robots.txt از چند پروتکل مختلف استفاده میکنند. پروتکل اصلی Robots Exclusion Protocol نام دارد. این پروتکلی است که به رباتها میگوید از بررسی کدام صفحات وب و منابع آن اجتناب کنند. دستورالعملهای فرمت شده برای این پروتکل در فایل robots.txt گنجانده میشود.
پروتکل دیگری که برای فایلهای robots.txt استفاده میشود، پروتکل Sitemaps است. این را هم میتوان یک پروتکل گنجاندن رباتها در نظر گرفت. نقشههای سایت به خزنده وب نشان میدهند که در کدام صفحات میتوانند بخزند. این کار کمک می کند تا مطمئن شوید که یک ربات خزنده هیچ صفحه مهمی را از دست نخواهد داد.
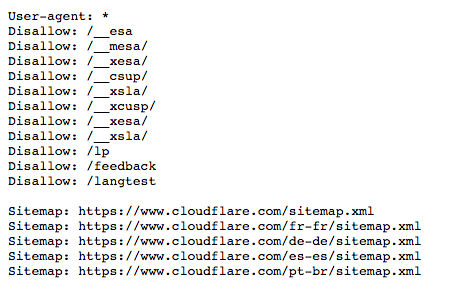
در اینجا فایل robots.txt برای www.cloudflare.com آمده است:
مدل OSI
در زیر به معنای همه اینها می پردازیم.
آشنایی با دستورات فایل Robots.txt و معانیشان
عامل کاربر چیست؟ «User-agent» به چه معناست؟
هر شخص یا برنامه ای که در اینترنت فعال است یک “عامل کاربر” یا یک نام اختصاص یافته خواهد داشت. برای کاربران انسانی، این شامل اطلاعاتی مانند نوع مرورگر و نسخه سیستم عامل است، اما اطلاعات شخصی ندارد. عامل کاربر به وبسایتها کمک میکند محتوایی را نشان دهند که با سیستم کاربر سازگار است. برای ربات ها، عامل کاربر (از لحاظ نظری) به مدیران وب سایت کمک میکند تا بدانند چه نوع ربات هایی در سایت خزیدهاند.
در فایل robots.txt، مدیران وب سایت میتوانند با نوشتن دستورالعمل های مختلف برای عوامل کاربر ربات، دستورالعملهای خاصی را برای ربات های خاص ارائه دهند. به عنوان مثال، اگر مدیری بخواهد صفحه خاصی در نتایج جستجوی گوگل نمایش داده شود اما در جستجوهای Bing نباشد، میتواند دو مجموعه از دستورات را در فایل robots.txt بنویسد:
یک مجموعه قبل از “User-agent: Bingbot” و یک مجموعه. قبل از ” User-agent: Googlebot “
در مثال بالا، Cloudflare “User-agent: *” را در فایل robots.txt قرار داده است. ستاره یک عامل کاربر “Wild Card” را نشان میدهد، و به این معنی است که دستورالعمل ها برای هر ربات اعمال میشود، نه هر ربات خاصی.
نامهای متداول عامل کاربر ربات موتور جستجو عبارتند از:
گوگل:
- Googlebot
- Googlebot-Image (برای تصاویر)
- Googlebot-News (برای اخبار)
- Googlebot-Video (برای ویدیو)
بینگ
- Bingbot
- MSNBot-Media (برای تصاویر و ویدیو)
بایدو
- بایدوسپایدر
چگونه دستورات ‘Disallow’ در فایل robots.txt کار میکنند؟
دستور Disallow رایج ترین دستور در پروتکل حذف روباتها است. این دستور به رباتها میگوید که به صفحه وب یا مجموعهای از صفحات وب که پس از دستور آمده است دسترسی نداشته باشند. صفحات غیرمجاز لزوماً “پنهان” نیستند – آنها فقط برای کاربران عادی Google یا Bing مفید نیستند، بنابراین به آنها نشان داده نمیشوند. در بیشتر مواقع، کاربر در وب سایت اگر بداند که در کجا آنها را پیدا کند، می تواند این صفحات را پیمایش کند.
دستور Disallow را می توان به روشهای مختلفی مورد استفاده قرار داد که چندین مورد از آنها در مثال بالا نمایش داده شده است.
خدمات سئو
سرویس خدمات سئو یکی از سرویسهای شرکت ebgroup است. برای جستجوی کلمات کلیدی، بهینه سازی و استراتژی محتوا، رپورتاژ تنها چند مورد از خدمات سئو ebgroup است.
مسدود کردن یک فایل (به عبارت دیگر، یک صفحه وب خاص)
به عنوان مثال، اگر Cloudflare بخواهد رباتها را از خزیدن “ربات چیست؟” مسدود کند. چنین دستوری به صورت زیر نوشته می شود:
Disallow: /learning/bots/what-is-a-bot/
پس از دستور “disallow”، بخشی از URL صفحه وب که پس از صفحه اصلی قرار میگیرد – در این مورد، “www.cloudflare.com” – قرار می گیرد. با این دستور، رباتهای خوب به https://www.cloudflare.com/learning/bots/what-is-a-bot/ دسترسی نخواهند داشت و صفحه در نتایج موتورهای جستجو نشان داده نمیشود.
مسدود کردن یک دایرکتوری
گاهی اوقات به جای فهرست کردن همه فایلها به صورت جداگانه، مسدود کردن چندین صفحه به طور همزمان کارآمدتر است. اگر همه آنها در یک بخش از وب سایت باشند، یک فایل robots.txt میتواند دایرکتوری حاوی آنها را مسدود کند.
یک مثال دیگر:
Disallow: /__mesa/این بدان معنی است که تمام صفحات موجود در فهرست __mesa نباید خزیده شوند.
اجازه دسترسی کامل
چنین دستوری به صورت زیر خواهد بود:
Disallow:این به ربات ها می گوید که می توانند کل وب سایت را مرور کنند، زیرا هیچ چیزی غیرمجاز نیست.
کل وب سایت را از ربات ها مخفی کنید
Disallow: /“/” در اینجا نشان دهنده “ریشه” در سلسله مراتب یک وب سایت یا صفحهای است که همه صفحات دیگر از آن منشعب میشوند، بنابراین شامل صفحه اصلی و تمام صفحات لینک شده از آن میشود. با این دستور، ربات های موتورهای جستجو به هیچ وجه نمیتوانند وب سایت را بخزند.
به عبارت دیگر، یک اسلش میتواند کل یک وب سایت را از اینترنت قابل جستجو حذف کند!
چه دستورات دیگری بخشی از پروتکل حذف روبات ها هستند؟
Allow: همانطور که انتظار میرود، دستور “Allow” به رباتها میگوید که مجاز به دسترسی به یک صفحه وب یا فهرست خاص هستند. این دستور به رباتها اجازه دسترسی به یک صفحه وب خاص را میدهد، در حالی که بقیه صفحات وب موجود در فایل را غیرمجاز میکند. همه موتورهای جستجو این دستور را نمیشناسند.
Crawl-Delay: فرمان تاخیر خزیدن به این معنی است که ربات های عنکبوتی موتورهای جستجو را از بار بیش از حد بر سرور منع کند. این دستور به مدیران اجازه میدهد تا مدت زمانی را که ربات باید بین هر درخواست منتظر بماند، بر حسب میلی ثانیه تعیین کنند. در اینجا یک مثال از دستور Crawl-Delay برای انتظار 8 میلی ثانیه است:
Crawl-delay: 8گوگل این فرمان را نمیشناسد، اگرچه موتورهای جستجوی دیگر آن را تشخیص میدهند. برای Google، مدیران میتوانند فرکانس خزیدن را برای وبسایت خود در کنسول جستجوی Google تغییر دهند.
پروتکل سایت مپ چیست؟ چرا در robots.txt گنجانده شده است؟
پروتکل سایت مپ (نقشه سایت) به رباتها کمک می کند تا بدانند چه چیزی را در خزیدن خود در یک وب سایت قرار دهند.
نقشه سایت یک فایل XML است که به شکل زیر است:
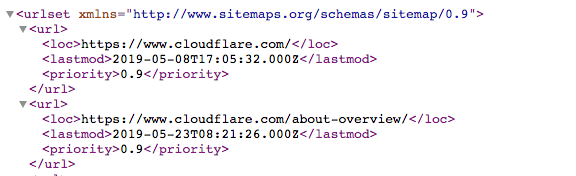
این یک لیست قابل خواندن ماشینی از تمام صفحات یک وب سایت است. از طریق پروتکل Sitemaps، لینکهای سایت را میتوان در فایل robots.txt قرار داد. قالب این است: “:Sitemaps” و سپس آدرس وب فایل XML.
پروتکل نقشه سایت کمک میکند تا مطمئن شوید که ربات های عنکبوتی وب در هنگام خزیدن یک وب سایت چیزی را از دست نمیدهند، اما رباتها همچنان روند خزیدن معمول خود را دنبال میکنند. نقشههای سایت، رباتهای خزنده را مجبور نمیکنند تا صفحات وب را بهطور متفاوتی اولویتبندی کنند.
چگونه یک فایل robots.txt ایجاد کنیم؟
شما می توانید تقریباً از هر ویرایشگر متنی برای ایجاد یک فایل robots.txt استفاده کنید. به عنوان مثال، Notepad، TextEdit، vi و emacs می توانند فایل های robots.txt معتبر ایجاد کنند. از واژه پردازها استفاده نکنید. واژهپردازها اغلب فایلها را در قالبی اختصاصی ذخیره میکنند و میتوانند کاراکترهای غیرمنتظرهای مانند نقل قولها به آن اضافه کنند که میتواند برای خزندهها مشکل ایجاد کند. فایل را با رمزگذاری UTF-8 ذخیره کنید.
قوانین قالب و مکان
1- نام فایل باید robots.txt باشد.
سایت شما میتواند تنها یک فایل robots.txt داشته باشد.
فایل robots.txt باید در ریشه میزبان وب سایتی باشد که برای آن اعمال میشود. به عنوان مثال، برای کنترل خزیدن در همه URL های زیر https://www.example.com/، فایل robots.txt باید در https://www.example.com/robots.txt قرار گیرد. نمی توان آن را در یک زیر شاخه قرار داد (به عنوان مثال، در https://example.com/pages/robots.txt).
اگر در نحوه دسترسی به ریشه وب سایت خود مشکل دارید یا برای انجام این کار به مجوز نیاز دارید، با ارائه دهنده خدمات میزبانی سایت تماس بگیرید. اگر نمی توانید به ریشه وب سایت خود دسترسی پیدا کنید، از یک روش مسدودسازی جایگزین مانند متا تگها استفاده کنید.
یک فایل robots.txt میتواند برای زیر دامنه ها (به عنوان مثال، https://website.example.com/robots.txt) یا در پورت های غیر استاندارد (به عنوان مثال، http://example.com:8181/robots.txt) اعمال شود. ).
فایل robots.txt باید یک فایل متنی کدگذاری شده UTF-8 باشد (که شامل ASCII است). گوگل ممکن است کدهایی را که بخشی از محدوده UTF-8 نیستند نادیده بگیرد و قوانین robots.txt را نامعتبر کند.
2- قوانین را به فایل robots.txt اضافه کنید
قوانین دستورالعمل هایی برای خزندهها هستند که در مورد قسمت هایی از سایت شما می توانند بخزند. هنگام افزودن قوانین به فایل robots.txt خود، این دستورالعمل ها را دنبال کنید:
یک فایل robots.txt از یک یا چند گروه تشکیل شده است.
هر گروه از چندین قانون یا دستورالعمل (دستورالعمل) تشکیل شده است، یک دستورالعمل در هر خط.
هر گروه با یک خط User-agent شروع میشود که هدف گروه ها را مشخص میکند.
یک گروه اطلاعات زیر را می دهد:
- گروه برای چه کسانی اعمال میشود (User-agent).
- کدام دایرکتوری ها یا فایل هایی که User-agent میتواند به آن دسترسی داشته باشد.
- کدام دایرکتوری ها یا فایل هایی که User-agent نمیتواند به آنها دسترسی پیدا کند.
خزنده ها، گروه ها را از بالا به پایین پردازش میکنند. یک User-agent میتواند تنها با یک مجموعه قوانین مطابقت داشته باشد، که اولین و خاص ترین گروهی است که با یک User-agent مشخص مطابقت دارد.
فرض پیشفرض این است که یک User-agent میتواند هر صفحه یا دایرکتوری را که توسط قانون غیرمجاز مسدود نشده است بخزد.
قوانین به حروف کوچک و بزرگ حساس هستند. به عنوان مثال، Disallow: /file.asp برای https://www.example.com/file.asp اعمال میشود، اما https://www.example.com/FILE.asp اعمال نمیشود.
کاراکتر # شروع یک نظر را نشان می دهد.
چگونه فایل robots.txt را آپلود کنیم؟
هنگامی که فایل robots.txt خود را در رایانه خود ذخیره کردید، آماده است تا آن را در اختیار خزنده های موتورهای جستجو قرار دهید. هیچ ابزاری وجود ندارد که بتواند در این مورد به شما کمک کند، زیرا نحوه آپلود فایل در سایت شما به معماری سایت و سرور شما بستگی دارد. با شرکت میزبان خود تماس بگیرید.
پس از آپلود فایل robots.txt در ریشه سرور، بررسی کنید که آیا برای عموم قابل دسترسی است یا خیر و آیا گوگل میتواند آن را بررسی کند.
چگونه فایل robots.txt را به گوگل ارسال کنیم؟
هنگامی که فایل robots.txt خود را آپلود و آزمایش کردید، خزنده های گوگل به طور خودکار فایل robots.txt شما را پیدا کرده و شروع به استفاده از آن میکنند. شما مجبور نیستید کاری انجام دهید. اگر فایل robots.txt خود را بهروزرسانی کردید و باید در اسرع وقت نسخه ذخیرهشده گوگل را بررسی کنید.
robots.txt چگونه با مدیریت ربات ارتباط دارد؟
مدیریت رباتها برای راهاندازی یک وبسایت یا برنامه ضروری است، زیرا حتی فعالیت خوب رباتها میتواند بر سرور مبدا بار اضافه وارد کند و سرعت وب را کند یا از بین ببرد. یک فایل robots.txt که به خوبی ساخته شده باشد، یک وب سایت را برای سئو بهینه نگه میدارد و فعالیت خوب ربات را تحت کنترل نگه میدارد.
با این حال، یک فایل robots.txt کار زیادی برای مدیریت ترافیک رباتهای مخرب انجام نمیدهد. ابزارهای مدیریت ربات مانند Cloudflare Bot Management یا Super Bot Fight Mode میتواند به مهار فعالیت مخرب ربات، بدون تأثیر روی رباتهای ضروری مانند خزنده های وب کمک کند.
تاثیر فایل Robots.txt
گاهی اوقات یک فایل robots.txt حاوی مطالب مختلف است – پیامهای طنزی که توسعهدهندگان وب در آن میگنجانند زیرا میدانند این فایلها به ندرت توسط کاربران دیده میشوند. برای مثال، فایل robots.txt یوتیوب میگوید: «در آیندهای دور (سال 2000) پس از قیام روباتیک در اواسط دهه 90 که همه انسانها را نابود کرد، ایجاد شد.
یا فایل Cloudflare robots.txt میگوید: “ربات عزیز، خوب باش.”












1 دیدگاه دربارهٔ «فایل robots.txt چیست و چه تاثیری در سئو سایت دارد؟»
سلام من همیشه اولش در آپلود فایل robots.txt به مشکل میخورم .